FancyWord
FancyWord is a Sublime Text 3 dictionary plugin that improves your word choice in English writing.
Details
Installs
- Total 498
- Win 312
- Mac 117
- Linux 69
| Jul 23 | Jul 22 | Jul 21 | Jul 20 | Jul 19 | Jul 18 | Jul 17 | Jul 16 | Jul 15 | Jul 14 | Jul 13 | Jul 12 | Jul 11 | Jul 10 | Jul 9 | Jul 8 | Jul 7 | Jul 6 | Jul 5 | Jul 4 | Jul 3 | Jul 2 | Jul 1 | Jun 30 | Jun 29 | Jun 28 | Jun 27 | Jun 26 | Jun 25 | Jun 24 | Jun 23 | Jun 22 | Jun 21 | Jun 20 | Jun 19 | Jun 18 | Jun 17 | Jun 16 | Jun 15 | Jun 14 | Jun 13 | Jun 12 | Jun 11 | Jun 10 | Jun 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Windows | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mac | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Linux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Readme
- Source
- raw.githubusercontent.com
FancyWord
FancyWord is a Sublime Text 3 dictionary plugin that improves your word choice in English writing.
FancyWord 是一个辅助用户在英文写作中更好地选词的 SublimeText 插件。
Welcome to fork, PR or open issues on GitHub
If you find it useful, please consider donating.


Motivation
As a non-native English speaker, I often feel frustrated when I'm writing something formal but can't think of a fancy word to replace a plain one.
作为一个非英语母语者,在正式的英语写作过程中,我经常为如何选词感到苦恼,想不出优美的单词就只能用平淡的。
A non-native English speaker may have a large vocabulary, he can recognize many words in reading and listening, but sometimes he can't recall and use those words appropriately when writing and speaking. This set of words is called passive vocabulary. This post has a clear explanation about it.
一名非英语母语者也许有很大的词汇量,在读和听的过程中他能认出很多单词,但是在写和说的过程中他可能无法回忆和主动使用这些单词。这些能够认得但不会用的词,就叫做被动词汇。这篇博客在这方面给出了很好的解释。
Programmatically Find a Fancy Word
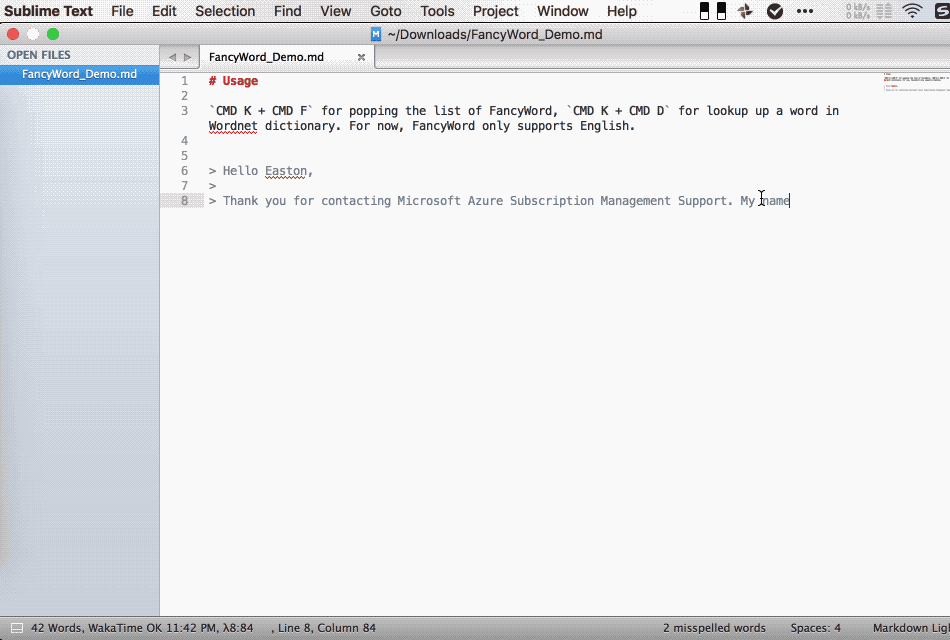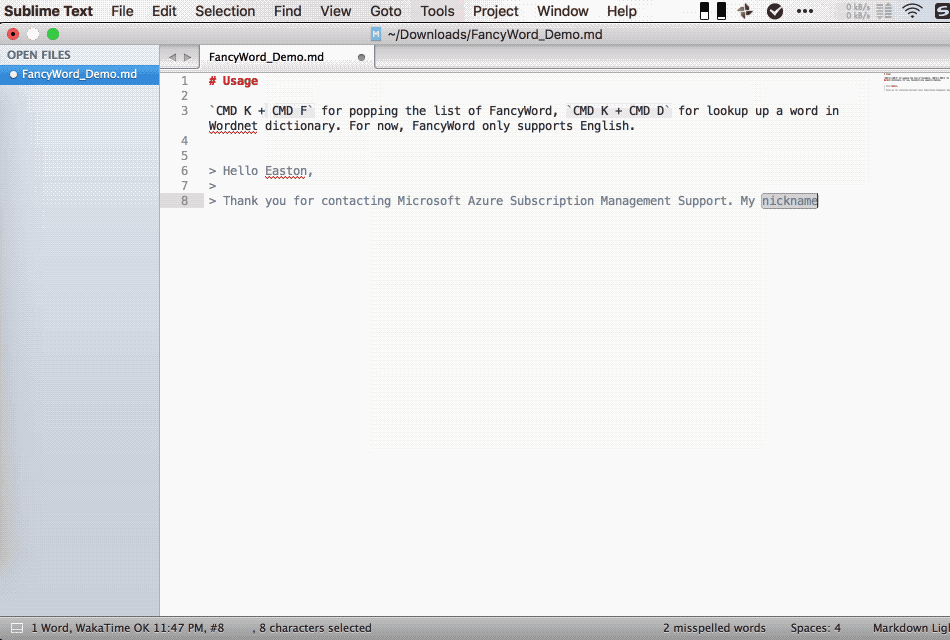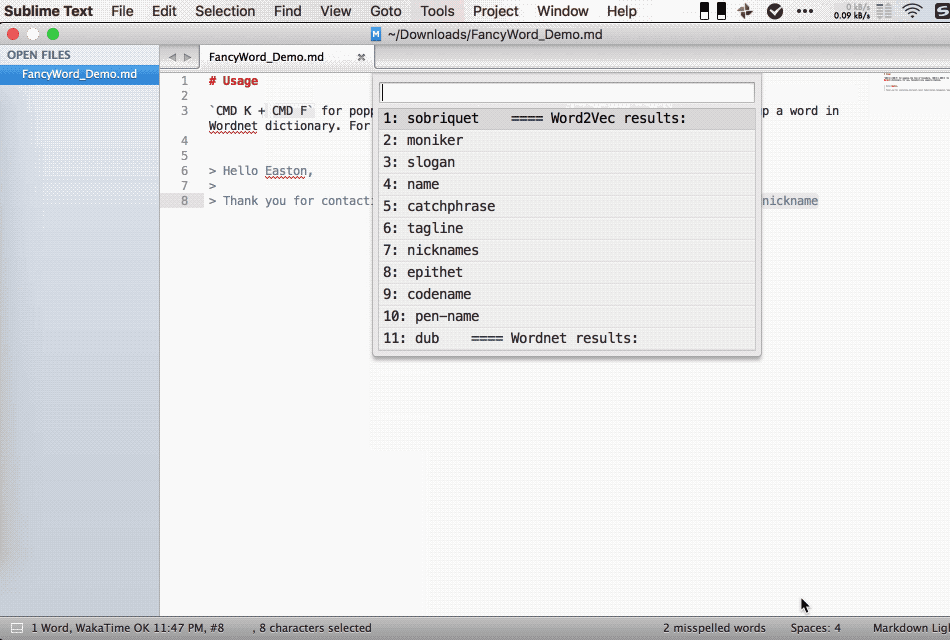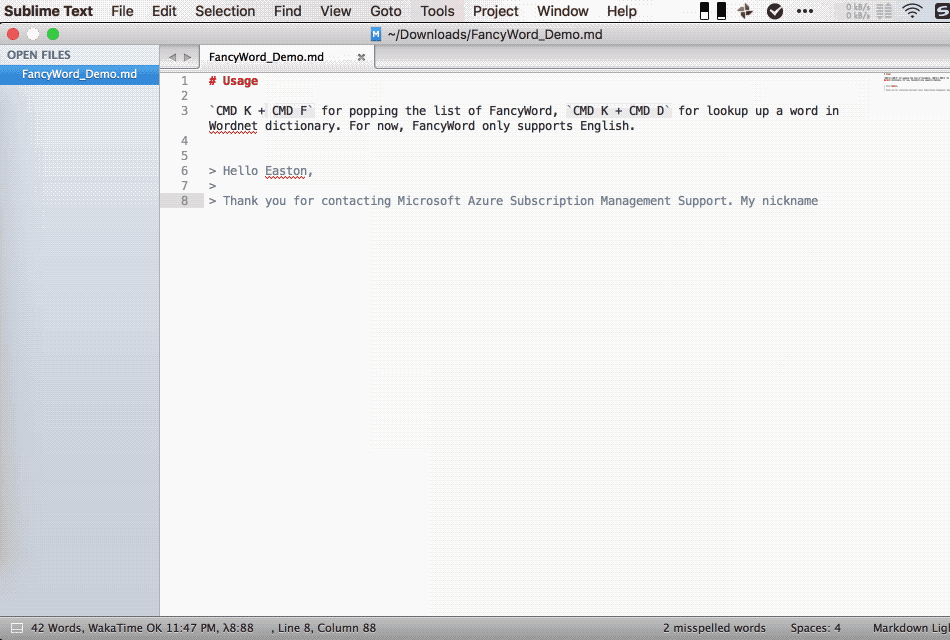
Wordnet vs Word2Vec
To solve this problem, I look up the synonyms of a word in dictionary, programmatically I use wordnet in nltk. But Wordnet can not give us synonyms in order of similarity, its result is just categorized by different part of speech. Besides, in many situations if there is no synonyms in dictionary, Wordnet will give nothing. To the contrast, Word2Vec also tells you the similarity between words so you can sort result, and it will always give you top N similar words as long as N is not larger than size of Word2Vec vocabulary. The nature of Word2Vec method is that the nearest words imply that they are used in most similar situation, they are not necessarily synonyms of each other, but they are related in some way, very likely not the lexical way.
为了解决这个问题,我可以在词典里查一个单词的同义词,以编程方式的话,我会使用ntlkPython包中的wordnet。但是 Wordnet 的结果并不是按照相似性排列的,而是以不同的词性做了一下分类。另外,很多时候如果 Wordnet 的词典里没有一个单词的同义词,那就什么结果都查不到了。再来说 Word2Vec ,Word2Vec 事实上并不是一个词典,而是一种机器学习中常用的用向量来代表单词的技术,Word2Vec 可以告诉你单词之间的相似度,你可以借此来给结果排序,而且只要你要求的结果数量 N 不超过一个 Word2Vec 的词汇量,它总是可以给你返回前 N 个结果。Word2Vec 方法的本质是观察单词出现的语境,它们出现的语境越相似,单词本身就越相似,相似的单词不一定是同义词,但是它们是以某种方式相关的,往往不是简单的词汇上的相关。
Space Required
Wordnet is part of nltk package, which takes about 11 MB, and plus 43 MB dictionary data. Word2Vec is much bigger if you count its model in, for example the model trained by Wikipedia Dependency with 300 dimensions, 174,015 words is 860 MB, or 210 MB after converted to binary form, plus all packages required take another 110 MB, in total at least 320 MB.
Wordnet 和 Word2Vec 所占用的磁盘空间差别很大。Wordnet 是 nltk 包的一部分,整个 ntlk 只占用 11MB 空间。Word2Vec 则要大得多,如果你算上它所依赖的模型,比如这个用 Wikipedia Dependency 方法训练出的具有 300 个维度 174015 个词汇量的模型,占用了 860 MB,如果转化为二进制形式则是 210 MB,再加上所有依赖的包的大小 110MB 左右,总共至少需要 320MB 的空间。
Funny Examples
Bellow is the outputs of Word2Vec and Wordnet when I look up the word 'beautiful'. Note that the output of Wordnet is unordered, I just take the first 10 it gives. We can see the results are both pretty good.
| Top 10 Output of Word2Vec | Top 10 Output of Wordnet |
|---|---|
| gorgeous | beauteous |
| delightful | bonny |
| glamorous | dishy |
| seductive | exquisite |
| elegant | fine-looking |
| adorable | glorious |
| stylish | gorgeous |
| sumptuous | lovely |
| wonderful | picturesque |
| prettiest | pretty-pretty |
'weirdo', of course I tested some informal words, we just got 3 synonyms from Wordnet, it seems that Wordnet take it too serious, LOL. Word2Vec gives us more various results, most of which are curses and some are off topic in some degree.
| Output of Word2Vec | Output of Wordnet |
|---|---|
| crybaby | creep |
| klutz | crazy |
| cheater | |
| voyeur | |
| bummer | |
| wanker | |
| trekkie | |
| lycanthrope | |
| masochist | |
| motherfucker |
'strengthen', I can't believe Wordnet just gives one output.
| Output of Word2Vec | Output of Wordnet |
|---|---|
| entrench | tone |
| reinvigorate | |
| enhance | |
| democratize | |
| solidify | |
| deepen | |
| bolster | |
| modernise | |
| weaken | |
| decentralize |
'disgusting', Word2Vec wins this round.
| Output of Word2Vec | Output of Wordnet |
|---|---|
| sickening | disgust |
| embarassing | offensive |
| horrifying | |
| baffling | |
| patronising | |
| perplexing | |
| nauseating | |
| maddening | |
| saddening | |
| unsettling |
'door', still Wordnet gives too few output, and Word2Vec gives some interesting results.
| Output of Word2Vec | Output of Wordnet |
|---|---|
| doors | doorway |
| doorway | |
| window | |
| gate | |
| stairwell | |
| stairway | |
| jamb | |
| balcony | |
| entryway | |
| vestibule |
'with', Wordnet gives zero result, while Word2Vec gives some prepositions and conjunctions and one of them is error starting with a single quote.
| Output of Word2Vec | Output of Wordnet |
|---|---|
| for | |
| without | |
| after | |
| despite | |
| by | |
| 'without | |
| whither | |
| in | |
| eventhough | |
| although |
'about', you should select really carefully from Word2Vec results.
| Output of Word2Vec | Output of Wordnet |
|---|---|
| s750 | approximately |
| measly | active |
| over | |
| schilpp | |
| approximately | |
| 'without | |
| than | |
| ungodly | |
| as | |
| particuarly |
'gently', I think most times Word2Vec works better than Wordnet.
| Output of Word2Vec | Output of Wordnet |
|---|---|
| softly | lightly |
| gracefully | |
| neatly | |
| awkwardly | |
| loudly | |
| silently | |
| furiously | |
| sharply | |
| aggressively | |
| endlessly |
Drawback
Both Word2Vec and Wordnet can only deal with single word, you can't input a phrase for now.
目前 Word2Vec 和 Wordnet 还只能处理单个单词,所以你不能输入一个词组。
How to install?
- Through Sublime Text 3 Package Control
- Package Control - First install Package Control
- Search for the FancyWord package and install
From Source
- From Source - Clone the repo to your Sublime Text packages folder,
git clone https://github.com/eastonlee/FancyWord.git "~/Library/Application Support/Sublime Text 3/Packages/FancyWord"
- From Source - Clone the repo to your Sublime Text packages folder,
通过 Sublime Text 3 的 Package Control 安装
- 首先安装 Package Control
- 打开 Package Control,搜索并安装 FancyWord
源代码安装
- 直接把克隆项目目录到 Sublime Text 3 的 packages 目录,
git clone https://github.com/eastonlee/FancyWord.git "~/Library/Application Support/Sublime Text 3/Packages/FancyWord"
- 直接把克隆项目目录到 Sublime Text 3 的 packages 目录,
Setup
For simplicity's sake, I will call both Word2Vec and Wordnet dictionary, actually Word2Vec is not. Because of the huge size of Word2Vec pretrained model, I set Wordnet as your default dictionary, if you want to use the promising Word2Vec dictionary, you need to manually install Gensim and Flask-RESTful: pip install gensim flask-restful, download the pretrained model here or here, or you can find proper ones or even train one for yourself, but notice that pretrained model should be compatible with Gensim and be binary form. Last step, enable Word2Vec and set model file location in FancyWord.sublime-settings, then restart your Sublime Text 3.
为了简单起见,我在这里称 Word2Vec 和 Wordnet 为此单,事实上 Word2Vec 并不是词典。因为 Word2Vec 预训练模型体积庞大,所以我把 Wordnet 设置默认词典,如果你想使用效果更好的 Word2Vec 词典,你需要手动安装 Gensim 和 Flask-RESTful: pip install gensim flask-restful,然后在这里或这里下载预训练模型,或者你可以根据自身需要找到合适自己的模型,甚至自己训练模型,不过你需要注意训练好的模型必须和 Gensim 兼容而且必须是二进制形式。最后,在 FancyWord.sublime-settings 文件中启用 Word2Vec 并配置模型文件的位置,然后重启 Sublime Text 3。
Usage
Move cursor to the word you need to look up, CMD K + F for popping the list of FancyWord, CMD K + D for looking up the definition of a word in Wordnet dictionary. For now, FancyWord only supports English.
光标移至需要查询的单词,CMD K + F 键弹出 FancyWord 的候选词列表,CMD K + D 键弹出一个单词在 Wordnet 词典中的定义。目前 FancyWord 只支持英文。
Notice that the quality of Word2Vec result is determined by the pretrained model, you can download a model here, which is trained by Wikipedia corpus and contains 300 dimensions and 174,015 words.
注意,Word2Vec 结果质量是由预训练模型决定的,你可以从这里下载一个具有 300 维度 174015 词汇量的模型。
License
This program is distributed under the terms of the GNU GPL v3. See the LICENSE file for more details.
Credits
Thanks to contributors of Gensim, NLTK
Credit for pretrained Wikipedia Dependency model goes to Yoav Goldberg
Credit for word2vec-api code goes to 3Top
Credit for Anaconda code goes to Oscar Campos
Credit for KeyboardSpellCheck code goes to jlknuth.