Requester
Powerful, modern HTTP/REST client built on top of the Requests library
Details
Installs
- Total 6K
- Win 3K
- Mac 2K
- Linux 1K
| Aug 3 | Aug 2 | Aug 1 | Jul 31 | Jul 30 | Jul 29 | Jul 28 | Jul 27 | Jul 26 | Jul 25 | Jul 24 | Jul 23 | Jul 22 | Jul 21 | Jul 20 | Jul 19 | Jul 18 | Jul 17 | Jul 16 | Jul 15 | Jul 14 | Jul 13 | Jul 12 | Jul 11 | Jul 10 | Jul 9 | Jul 8 | Jul 7 | Jul 6 | Jul 5 | Jul 4 | Jul 3 | Jul 2 | Jul 1 | Jun 30 | Jun 29 | Jun 28 | Jun 27 | Jun 26 | Jun 25 | Jun 24 | Jun 23 | Jun 22 | Jun 21 | Jun 20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Windows | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mac | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Linux | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Readme
- Source
- raw.githubusercontent.com
Requester: HTTP Client for Humans


Requester is a modern, team-oriented HTTP client for Sublime Text 3 that combines features of apps like Postman, Paw and HTTPie with rock-solid usability and the secret sauce of Requests. 🌟
- Super classy syntax
- Easily set request body, query params, custom headers, cookies
- Support for sessions, authentication
- Forms and file uploads, Wget-style downloads
- HTTPS, proxies, redirects, and more
- Intuitive, modern UX
- Define environment variables with regular Python code
- Execute requests and display responses in parallel, or chain requests
- Edit and replay requests from individual response tabs, page through past requests
- Explore hyperlinked APIs from response tabs
- Fuzzy searchable request collections and request history
- Formatted, colorized output with automatic syntax highlighting
- Clear error handling and error messages
- Full GraphQL support
- Built for teams
- Version and share requests however you want (Git, GitHub, etc)
- Export requests to cURL or HTTPie, import requests from cURL
- Lightweight, integrated test runner with support for JSON Schema
- Export Requester tests to runnable test script
- AB-style benchmarking tool
- Runs on Linux, Windows and macOS/OS X
- Highly extensible
If you're looking for an HTTP client you should try Requester even if you've never used Sublime Text.
Installation
- Download and install Sublime Text 3.
- Install Package Control for Sublime Text.
- Open the command palette shift+cmd+p and type Package Control: Install Package.
- Search for Requester (not
Http Requester) and install it.
Getting Started
Open the interactive tutorial in Sublime Text! Look for Requester: Show Tutorial in the command palette.
Or, open a file and insert the following.
requests.get('https://jsonplaceholder.typicode.com/albums')
requests.post('https://jsonplaceholder.typicode.com/albums')
get('https://jsonplaceholder.typicode.com/posts') # 'requests.' prefix is optional
post('jsonplaceholder.typicode.com/posts') # as is the URL scheme
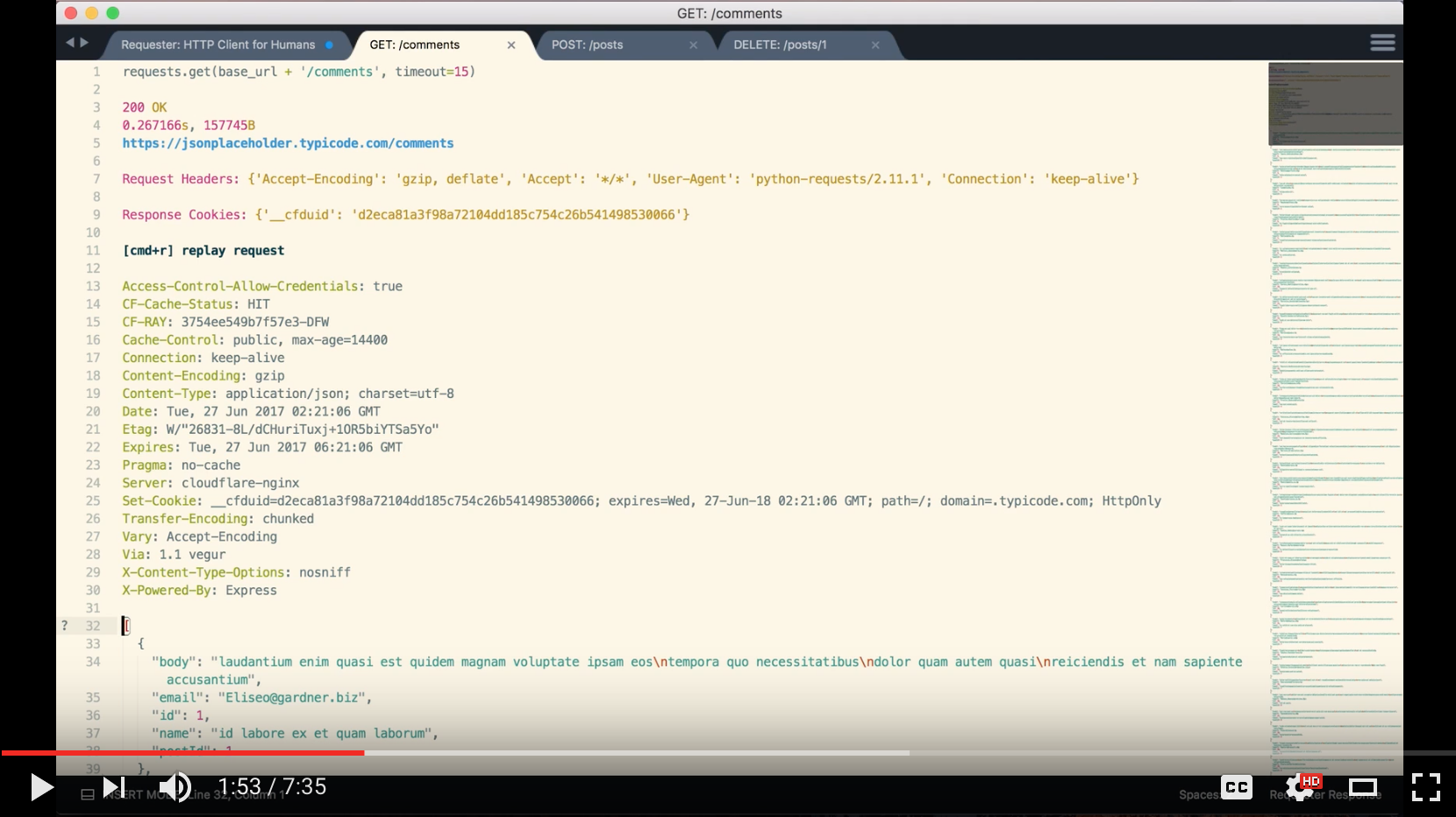
Place your cursor on one of the lines and hit ctrl+alt+r (ctrl+r on macOS). Or, look for Requester: Run Requests in the command palette shift+cmd+p and hit Enter. A response tab will appear, with a name like GET: /albums.
Head to the response tab and check out the response. Hit ctrl+alt+r or ctrl+r (ctrl+r or cmd+r on macOS) to replay the request. You can edit the request, which is at the top of the file, before replaying it.
Now, go back to the requester file and highlight all 5 lines, and once again execute the requests. Nice, huh?
Multiline Requests, Request Body, Query Params
post(
'httpbin.org/post',
json={'name': 'Jimbo', 'age': 35, 'married': False, 'hobbies': ['wiki', 'pedia']}
)
get(
'httpbin.org/get',
params={'key1': 'value1', 'key2': 'value2'}
)
Body, Query Params, and Headers are passed to requests as dictionaries. And for executing requests defined over multiple lines, you have two options:
- fully highlight one or more requests and execute them
- place your cursor inside of a request and execute it
Try it out.
Documentation
Wanna see everything else Requester does? Detailed, fuzzy searchable documentation here.
Release Notes
See Requester's version history here.
Why Requester?
Requester combines features from applications like Postman, Paw, Insomnia and HTTPie with the elegance and power of Requests and rock-solid UX of Sublime Text.
Requester leans on Requests as much as possible. This means Requester does most anything Requests does, which means it does most anything you need to explore, debug, and test a modern API.
It also means Requester uses an extensively documented, battle-tested library famed for its beauty. If you don't know how to do something with Requester, there are thousands of blog posts, articles and answers on Stack Overflow that explain how to do it.
Apart from being feature-rich, Requester is built for speed and simplicity. I was a Postman user before writing Requester, and I got tired of, for example, having to click in 4 places to add or change an env var. With Requester you might have to move your cursor up a few lines.
Request navigation and history, which use Sublime Text's blistering fast fuzzy match, are especially powerful. Jump between requests and request groups in your requester file. Hop between open response tabs. Find the exact version of a request you executed a week ago. It's all lightning fast.
The paid collaboration features of HTTP client apps, such as sharing and versioning, are not only free in Requester, they're better. Requester works with text files, and as good as the developers at Postman and Paw are, they don't beat GitHub at collaboration, and they don't beat Git at version control.
Need to share requests with someone who doesn't use Requester? Exporting your requests to cURL or HTTPie takes a few seconds. Ditto with importing requests from cURL, which means it's trivial to grab AJAX requests sent by your browser and pull them into Requester.
Requester is cross-platform and built for teams. If you debug web APIs for work or for fun, try it. Try it even if you don't use Sublime Text. You'll have to switch between two text editors, but you already have to switch between your editor and your HTTP client, and I'm betting you'll like Requester more. ✨✨