SAS Syntax and Theme
A Sublime Text 3 package for SAS syntax highlighting and the corresponding SAS Theme
Details
Installs
- Total 18K
- Win 13K
- Mac 4K
- Linux 2K
| Jul 27 | Jul 26 | Jul 25 | Jul 24 | Jul 23 | Jul 22 | Jul 21 | Jul 20 | Jul 19 | Jul 18 | Jul 17 | Jul 16 | Jul 15 | Jul 14 | Jul 13 | Jul 12 | Jul 11 | Jul 10 | Jul 9 | Jul 8 | Jul 7 | Jul 6 | Jul 5 | Jul 4 | Jul 3 | Jul 2 | Jul 1 | Jun 30 | Jun 29 | Jun 28 | Jun 27 | Jun 26 | Jun 25 | Jun 24 | Jun 23 | Jun 22 | Jun 21 | Jun 20 | Jun 19 | Jun 18 | Jun 17 | Jun 16 | Jun 15 | Jun 14 | Jun 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Windows | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mac | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| Linux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
Readme
- Source
- raw.githubusercontent.com
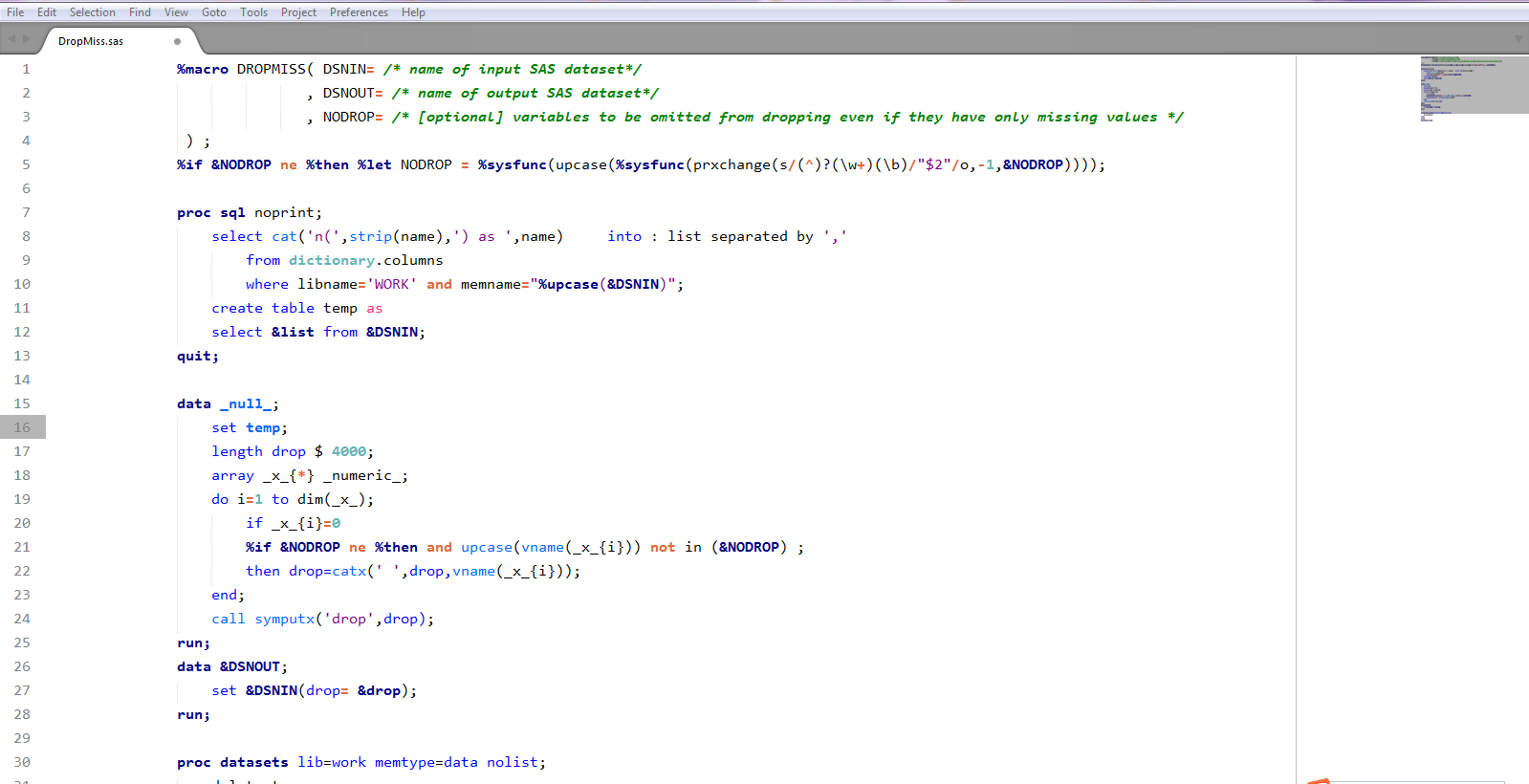
SAS Syntax Highlight and Theme Package for Sublime Text 3
What is this?
A Sublime Text package for SAS syntax highlight and color scheme which mimic the SAS system.
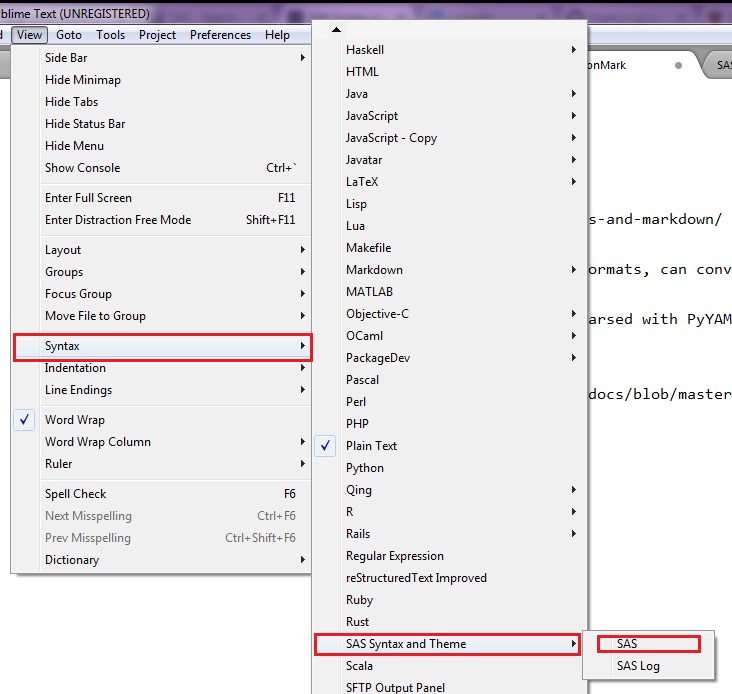
How to Install
Via Package Control
The easiest way to install is using Sublime Package Control, where the package is listed as SAS-Syntax-and-Theme.
- Open Command Palette using menu item
Tools -> Command Palette...(⇧⌘P on Mac) - Choose
Package Control: Install Package - Find
SAS Syntaxand hit Enter
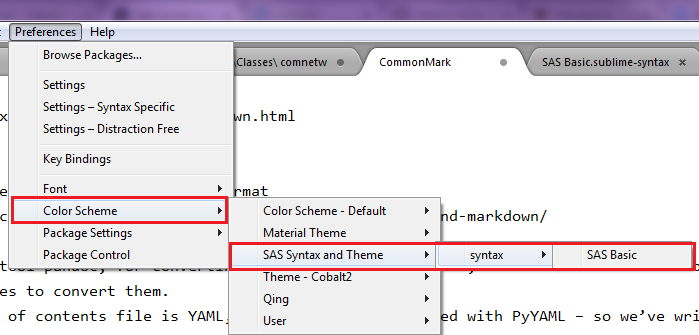
Manual
You can also install the theme manually:
- Download the .zip
- Unzip and rename the folder to
SAS-Syntax-and-Theme - Copy the folder into
Packagesdirectory, which you can find using the menu itemSublime Text -> Preferences -> Browse Packages...
 ## Thanks
The SAS Programming Package developed by
## Thanks
The SAS Programming Package developed by